《算法图解》读书笔记4-分治思想和快排
algorithms Linux分而治之(Divide and Conquer)
所谓分而治之,分为分解问题,但我们目的是解决大问题,所有还有将分解后得到的结果贡献回大问题,最终使得我们解决大问题。
分而治之的思想是采用了递归的思想,将原问题分成几个规模较小但是类似于原问题的子问题, 通过递归的方式来求解这些小问题,最后将子问题的解合并来得到原问题的解。分治思想的本质是我们中学时候学的数学归纳法。
书上提到,使用分治思想解决问题的过程包括两个步骤,其实应该是三个步骤:
- 找出基线条件,这种条件必须尽可能简单。
- 不断将问题分解为子问题(或者说缩小规模),直达符合基线条件。
- 合并子问题的结果,得到最终问题的解(利用系统栈的特性实现过程状态的记录)

快速排序
分治思想并非可用于解决问题的算法,而是一种解决问题的思路。快速排序就是一种使用分治思想来排序的算法。
快速排序使用分治思想根据基准值(pivot)把一个列表分为两个子列表,然后继续对子列表使用快速排序,直到抵达基线条件,然后再合并结果得到有序的列表。
步骤:
- 从数列中挑出一个元素,称为"基准"(一般选择 list[0])
- 分割列表,所有小于基准值的元素放在基准值的左边,大于基准值的放在右边。这个称为**分区(partition)**操作
- 对左右两边的子序列继续使用快速排序,结果列表相加即可。中间过程状态交给系统的栈去记录
快排实现方式
方法 1 gist 地址
def qsort(arr):
# 基线条件
if len(arr) < 2:
return arr
else:
# 基准值
pivot = arr[0]
less = []
greater = []
pivot_list = []
for i in arr:
if i < pivot:
less.append(i)
elif i > pivot:
greater.append(i)
else:
pivot_list.append(i)
return qsort(less) + pivot_list + qsort(greater)
方法一是最常规的写法,最好按照方法一的写法,将大于小于等于三种情况区分开,可以减少循环和递归次数。
优化版
上面的方法每次递归都需要重新建立新的列表,这样会提高算法的空间复杂度。还有一种优化的版本,直接在序列内部做交换动作,实现排序:
def quicksort(lst, lo, hi):
if lo < hi:
p = partition(lst, lo, hi)
quicksort(lst, lo, p-1)
print("list:", lst)
quicksort(lst, p+1, hi)
def partition(lst, lo, hi):
pivot = lst[hi]
left = lo
right = hi - 1
while True:
while lst[left] < pivot:
left += 1
while right > 0 and lst[right] > pivot:
right -= 1
if left >= right:
break
else:
# 交换位置
lst[left], lst[right] = lst[right], lst[left]
# 将基准值放到中间位置
if left != hi:
lst[hi] , lst[left] = lst[left], lst[hi]
return left
if __name__ == "__main__":
arr = [1,4,23,6,2,8,61,22,67,511]
quicksort(arr, 0, len(arr)-1)
print(arr)
#[out]: [1, 2, 4, 6, 8, 22, 23, 61, 67, 511]
这中实现方式不是很好理解,附上一张算法实现动态过程图:
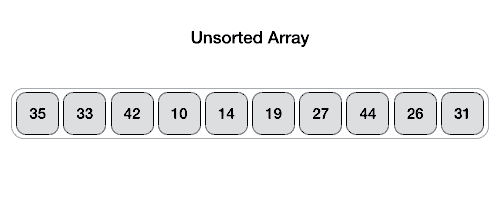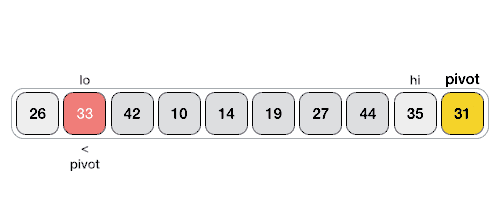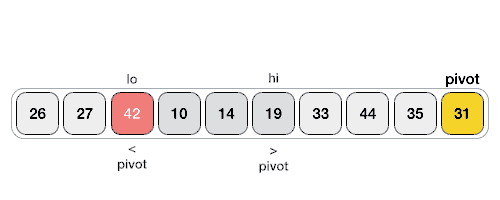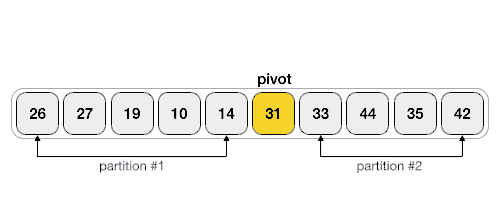
下面列出几个网上带点“骚”色彩的写法,仅供参考。参考地址
方法 2
所有表达式放在一行内。
def qsort(L):
return (qsort([y for y in L[1:] if y < L[0]]) + L[:1] + [y for y in L[1:] if y == L[0] + qsort([y for y in L[1:] if y > L[0]])) if len(L) > 1 else L
方法 3
基准的随机取,这样有可能会选中中间值,减少递归次数,也有可能选中极值。我们设定默认选中第一个,也是随机选择的一种形式。
from random import *
def qSort(a):
if len(a) <= 1:
return a
else:
q = choice(a) #基准的选择不同于前,是从数组中任意选择一个值做为基准
return qSort([elem for elem in a if elem < q]) + [q] * a.count(q) + qSort([elem for elem in a if elem > q])
方法 4
真正的一行代码完成排序,使用匿名函数,def都懒得写了。
qs = lambda xs : ( (len(xs) <= 1 and [xs]) or [ qs( [x for x in xs[1:] if x < xs[0]] ) + [xs[0]] + qs( [x for x in xs[1:] if x >= xs[0]] ) ] )[0]
合并排序
书中并没有细讲合并排序(又叫归并排序),但是个人觉得合并排序相对于快排会更好点。这两个排序的时间复杂度就好比我们理财,一个是存银行吃利息,一个是买股票。合并排序就是在存银行的收益稳定,时间复杂度稳定为 O(nlog(n))),特点就是“稳定”。快速排序就是买股票,你不知道你买完以后是涨还是跌,运气好了时间复杂度为 O(nlog(n)),运气不好时间复杂度就是 O(n**2),因为快排的基准值也是随机选择的,所以快排的平均运行时间复杂度就为 O(nlog(n))。
所以可以看出,合并排序是一个稳定的算法,快排是一个不稳定的算法。
排序步骤
- 从序列中间分割为两个序列。(合并排序的分治思想和快排有点不同,之所以称为稳定的算法,就因为每次从序列中间分割)
- 分割后的子序列,继续递归分割,直到抵达基线条件。
- 将子序列的结果合并返回
合并排序实现
# 合并
def merge(l1, l2):
index1 = index2 = 0
r = []
while index1 < len(l1) and index2 < len(l2):
if l1[index1] < l2[index2]:
r.append(l1[index1])
index1 += 1
else:
r.append(l2[index2])
index2 += 1
if index1 == len(l1):
r += l2[index2:]
if index2 == len(l2):
r += l1[index1:]
return r
# 分解
def merge_sort(l):
if len(l) <= 1:
return l
middle = len(l) // 2
l1 = merge_sort(l[:middle])
l2 = merge_sort(l[middle:])
return merge(l1, l2)
算法时间复杂度比较
最后摆一张书中的算法时间复杂度比较的图,可以一目了然的看出各种算法效率。

— EOF —